

[Riproduciamo un articolo di Steven Struhl, autore per Apogeo di AI Marketing, disponibile in tutte le librerie fisiche e digitali. Il post originale, Artificial Intelligence: Hiding in Plain Sight, si può reperire sul sito KoganPage].
Prima di poter parlare di dove troviamo l’intelligenza artificiale (AI), dobbiamo definire il termine AI in quanto tale. È più difficile di quanto sembri. La maggior parte di noi concorderà sul fatto che possiamo parlare di AI anche senza robot che viaggiano per il mondo a discettare di filosofia. Da qui in avanti, sembra mancare un consenso chiaro. Un giornalista ha visitato Alphabet (già Google), l’epicentro dell’intelligenza artificiale, e ha chiesto spiegazioni a chi ci lavorava. Alcune delle risposte:
Dovresti proprio parlare con qualcun altro.
No grazie. Mi spiace. Buona fortuna.
Non saprei. Passo.
È il machine learning.
Lavoro a Yahoo…
Nel capitolo 1 di AI Marketing proponiamo una definizione, se non esauriente, almeno funzionale. Per intelligenza artificiale si intende in modo ampio qualunque cosa faccia una macchina per reagire all’ambiente circostante allo scopo di rendere massime le sue probabilità di successo.
Le macchine che usiamo sono computer e e programmiamo in modo che riconoscano schemi complessi oltre la nostra percezione, per aiutarci a prendere decisioni migliori. Non è avere un robot che lavora al posto nostro (non ancora), quindi siamo noi a dover decidere come utilizzare le informazioni in arrivo dalla macchina.

Meglio partire dalla definizione.
Chi è chi
È fuori di dubbio che intelligenza artificiale e machine learning, se non la stessa cosa, siano due cose sostanzialmente sovrapposte. Questo naturalmente suscita un altro interrogativo: che cosa voglia dire machine learning. Questa definizione cambia assieme a chi risponde. Su un articolo che dichiarava di insegnare machine learning ho letto di regressione e clustering come metodi avanzati di machine learning.
Sono due degli approcci analitici più apprezzati e longevi. La regressione si usava già quando di computer neanche si parlava. Anche con una definizione meno ampia, il machine learning ci accompagna da decenni. Ha lavorato dietro le quinte così come in prima fila, per risolverci problemi che altrimenti non avremmo potuto affrontare.
L’intelligenza artificiale, pura e cristallina, ha più spazio nelle nostre vite di quanto sospettiamo. Per esempio, la classification tree analysis fa uso abituale di algoritmi che verificano la significatività statistica, così raffinati che sono stati classificati intelligenza artificiale. Gli alberi di classificazione, ricordo, frammentano ripetutamente un campione in sottogruppi più piccoli. A ogni passo della procedura, i punteggi di qualche variabile predittiva portano a gruppi con punteggi maggiori o minori riferiti a qualche soglia o variabile in uscita.
Colazione da classifica
Per stare sul concreto, supponiamo di voler sapere quali famiglie con certe caratteristiche demografiche hanno consumato in particolare una certa marca di cereali per la colazione. Conosciamo i livelli di consumo di svariate centinaia di migliaia di famiglie e 46 indicatori demografici delle suddette, come posizione geografica, numero ed età dei figli, reddito, etnia eccetera (dati di questo tipo, almeno in Stati Uniti e Regno Unito, si possono facilmente acquistare per comporre il dataset che si desidera).

Il lavoro dell’albero di classificazione consiste nel considerare tutte queste variabili e i modi in cui usarle per dividere il campione in sottogruppi. Supponiamo che il consumo medio di quei cereali ammonti a 21 confezioni per famiglia. La procedura, dopo avere scandito tutte le possibili variabili, suggerirebbe come risultato che il tipo di città sia la variabile più indicata per trovare differenze e che il contrasto maggiore si otterrebbe raggruppando da una parte gli abitanti in città e nelle zone rurali (consumo medio 16 scatole) e dall’altra parte l’hinterland (consumo medio 28 scatole). In altre parole, la cintura extraurbana consuma il 175 percento rispetto a tutte le altre aree.
Ars combinatoria
A prima vista, come risultato, può sembrare poca cosa. Dopotutto i modi per combinare tre gruppi sono solo quattro, nel nostro caso città-campagna/hinterland, città/hinterland-campagna, città-hinterland/campagna e città/hinterland/campagna. Se però consideriamo la scansione di tutte le altre variabili, per esempio il numero di figli che potrebbe variare tra zero e magari dieci, il numero di combinazioni diviene improvvisamente astronomico. Risulta inoltre diabolicamente complicato confrontare la significatività di variabili che possono essere divise in molti modi con quella di altre variabili che invece hanno una sola divisione possibile, o poche. Per esempio, la variabile pensionato ha solo due valori possibili, sì e no. La difficoltà di queste comparazioni afflisse gravemente la primissima forma di analisi dell’albero di classificazione, AID. Risultava sempre che le migliori variabili erano quelle divisibili nel maggior numero di modi. Questa debolezza era talmente grave che gli alberi di classificazione vennero considerati un metodo debole e inaffidabile anche anni dopo che nuovi algoritmi avevano eliminato il problema.
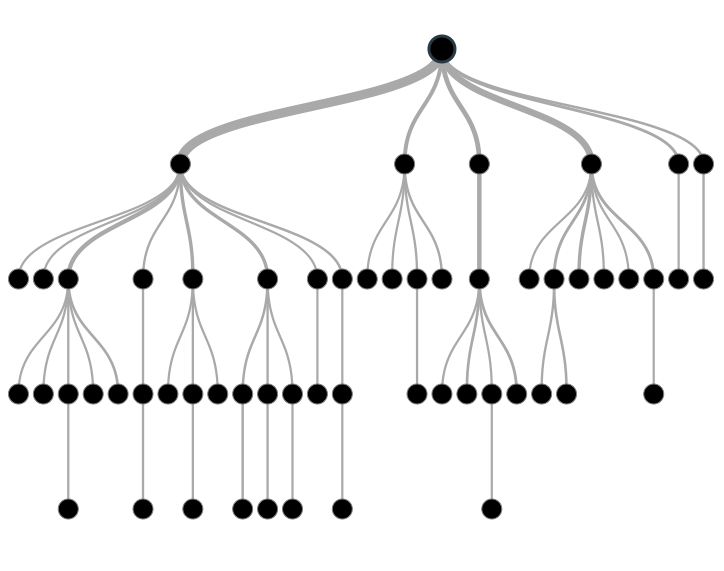
Divide et impara, è il principio base dell’analisi degli alberi di classificazione.
Il primo algoritmo veramente robusto fu presentato in una conferenza del 1991 sull’intelligenza artificiale. Da allora i progressi nella costruzione intelligente degli alberi hanno continuato a rafforzare i metodi esistenti.
Grandi problemi, grandi soluzioni
Il machine learning ha oltretutto rafforzato altri metodi già potenti. Per esempio, Discrete Choice Modeling e Conjoint Analysis sono stati estesi in modo sostanziale grazie all’impiego di un metodo di machine learning chiamato Hierarchical Bayesian Analysis. Si tratta di una applicazione ad alta intensità di calcolo, che ancora oggi può richiedere ore prima di fornire una soluzione (sono metodi che permettono di prevedere la risposta a centinaia o migliaia di prodotti, servizi o messaggi alternativi). Ora possiamo risolvere problemi più grandi e complessi di quanto sia mai stato possibile. In AI Marketing spieghiamo come questo accada. Tutti questi metodi, e altri descritti nel libro, mostrano che intelligenza artificiale e/o machine learning hanno svolto ruoli preziosi nel distinguere schemi nei dati e permetterci di prendere decisioni migliori. Questi utilizzi quotidiani, dove definiamo il problema e il campo di investigazione per lasciare sbrigare il lavoro pesante al computer, potrebbero costituire i migliori modelli per i futuri sviluppi delle applicazioni di intelligenza artificiale.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo
