

Machine learning, non intelligenza artificiale
Stando ai racconti di fantascienza, l’invenzione dell’intelligenza artificiale dovrebbe condurre inevitabilmente a guerre apocalittiche fra le macchine e i loro creatori. Le storie partono tutte dalla realtà di oggi: i computer imparano le regole dei giochi più semplici, come il tris (tic-tac-toe) e poi ad automatizzare dei compiti di routine. Ma il tempo passa, e alle macchine viene affidato il compito di controllare il traffico e le comunicazioni, poi i droni e infine i missili… L’evoluzione delle macchine entra in una tragica spirale quando i computer divengono senzienti e imparano a decidere e a imparare autonomamente. Non avendo quindi più bisogno di programmatori umani, non trovano nulla di meglio da fare che eliminare il genere umano.
Fortunatamente, almeno fino a questo momento, le macchine hanno ancora bisogno dei nostri input.
Anche se le impressioni relative al machine learning possano essere dipinte con questi colori sinistri, gli algoritmi impiegati oggi sono troppo specifici per pensare che possano essere generalizzati al punto di sviluppare un’autocoscienza. L’obiettivo del machine learning, oggi, non è quello di creare un cervello artificiale, ma piuttosto quello di assisterci nel nostro tentativo di comprendere la grande massa di dati oggi disponibili e trarne informazioni utili.

Le origini del machine learning
Fin dalla nascita, siamo letteralmente sommersi di dati. I nostri sensori fisici, gli occhi, le orecchie, il naso, la lingua e i nervi, si trovano costantemente a essere raggiunti da dati grezzi che il nostro cervello traduce in immagini, suoni, odori, gusti e senso del tatto. Grazie alle parole, siamo anche in grado di condividere queste esperienze con altri.
Dall’avvento della lingua scritta, le osservazioni umane hanno potuto essere registrate. I cacciatori monitoravano i movimenti delle prede; i primi astronomi registravano l’allineamento dei pianeti e delle stelle; e i governanti registravano i pagamenti delle tasse, le nascite e le morti. Al giorno d’oggi, tali osservazioni, e molte altre ancora, sono sempre più automatizzate e registrate in modo sistematico all’interno di sempre più ricchi database.
L’invenzione dei sensori elettronici ha ulteriormente contribuito a un’esplosione in termini di volume e ricchezza dei dati registrati. Sensori specializzati, come videocamere, microfoni, nasi chimici, lingue elettroniche e sensori di pressione imitano la capacità umana di vedere, udire, odorare, gustare e percepire sulla pelle. Questi sensori elaborano i dati in modo molto differente da quanto farebbe un essere umano. A differenza di quanto accade per l’attenzione limitata e soggettiva di un essere umano, un sensore elettronico non si ferma mai e non ha emozioni a controllare le sue percezioni.
Apprendimento automatico per grandi masse di dati
Questo vero diluvio di dati ha condotto alcuni ad affermare che siamo entrati nell’era dei big data, ma quel nome forse non è del tutto corretto. Gli esseri umani sono sempre stati circondati da grandi quantità di dati. Ciò che rende unica la nostra era è che abbiamo enormi quantità di dati registrati, molti dei quali accessibili direttamente tramite computer. Dataset sempre più grandi e interessanti sono sempre più accessibili e a portata di mano, tramite una semplice ricerca web. Questa grande ricchezza di informazioni ha la potenzialità di informare le nostre azioni, offrendoci un modo sistematico per acquisire il senso dei dati che abbiamo a disposizione.
Il campo di studi coinvolto nello sviluppo di algoritmi computerizzati in grado di trasformare i dati in azioni intelligenti si chiama machine learning: l’apprendimento automatico. Questo campo trae la sua origine in un ambiente in cui i dati disponibili, i metodi statistici e la potenza di calcolo crescono ed evolvono simultaneamente. La crescita nel volume dei data necessitava di maggiore potenza di calcolo, che a sua volta ha dato origine allo sviluppo di metodi statistici atti ad analizzare questi grossi dataset. Ciò ha creato un ciclo di avanzamenti tecnologici che ha consentito la raccolta di dati sempre più numerosi e interessanti, e arriviamo così all’oggi, in cui abbiamo a disposizione innumerevoli flussi di dati su, praticamente, ogni argomento immaginabile.
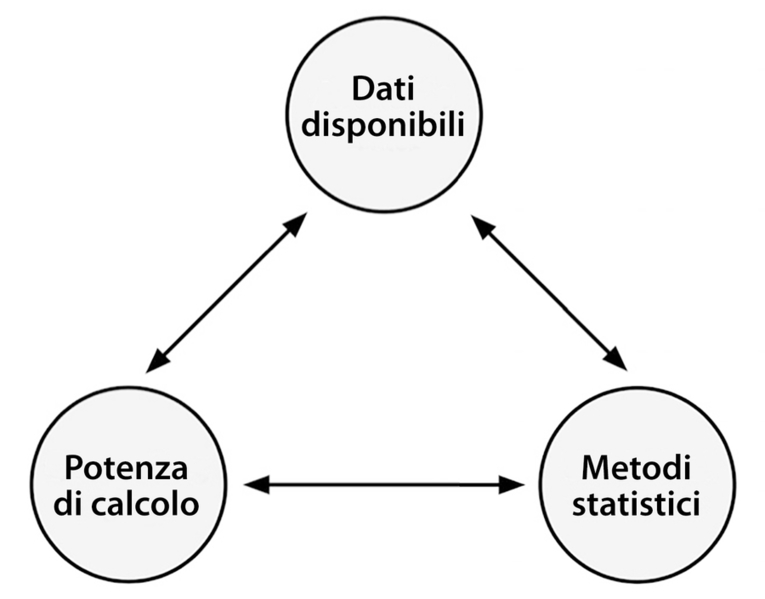
Il ciclo di avanzamento che ha reso possibile il machine learning.
Un parente stretto del machine learning, il data mining, si occupa della generazione di nuove conoscenze da grandi database. Il data mining prevede una ricerca sistematica di elementi di intelligenza utile. Sebbene vi siano alcuni disaccordi sull’entità della sovrapposizione fra machine learning e data mining, un possibile elemento di separazione consiste nel fatto che il machine learning si occupa di insegnare ai computer a utilizzare i dati per risolvere un problema, mentre il data mining si occupa di insegnare ai computer a identificare dei pattern, degli schemi che gli esseri umani utilizzeranno poi per risolvere un problema.
Usi e abusi del machine learning
Molti hanno sentito parlare di Deep Blue, un computer giocatore di scacchi che nel 1997 fu il primo a vincere una partita contro un campione del mondo. Un altro famoso computer, Watson, sconfisse due avversari umani in un gioco a quiz televisivo, Jeopardy, nel 2011. Sulla base di questi stupefacenti risultati, alcuni hanno ipotizzato che l’intelligenza dei computer sostituirà gli operatori umani nelle professioni che riguardano la tecnologia dell’informazione, così come le macchine hanno sostituito i lavoratori nei campi e nelle catene di montaggio.
La verità è che anche se le macchine hanno raggiunto risultati così impressionanti, sono tuttora relativamente limitate nella loro capacità di comprendere a fondo un problema. Esse sono pura potenza di calcolo intellettiva, ma senza direzione. Un computer può anche essere più abile di un essere umano di trovare subdoli schemi all’interno di grandi database, ma avrà comunque bisogno di un essere umano per motivare la sua analisi e trasformarne i risultati in un’azione significativa.
Le macchine non sono brave a porre domande e nemmeno sanno quali domande porre. Sono molto più brave a rispondere alle domande, sempre che la domanda sia formulata in un modo che il computer sia in grado di comprendere. Gli attuali algoritmi di machine learning fanno per l’essere umano quello che un segugio fa per il suo addestratore: il senso dell’olfatto del cane può anche essere molto più sviluppato di quello del suo padrone, ma senza un’accurata indicazione, il segugio potrebbe inseguire la sua coda.
I successi del machine learning
Il machine learning può avere particolare successo quando estende, piuttosto che sostituire, le conoscenze specializzate di un esperto sul campo. Può funzionare con i medici, in prima linea nel tentativo di debellare il cancro; assiste gli ingegneri e i programmatori nei loro tentativi di creare abitazioni e automobili più intelligenti; e aiuta gli scienziati sociali a costruire conoscenze sul funzionamento delle società.

Gli algoritmi di machine learning sono strumenti potenti, ma richiedono di procedere in una direzione precisa.
Con questi obiettivi, il machine learning viene impiegato da innumerevoli aziende, laboratori, ospedali ed enti governativi. Ogni attività che generi o aggreghi i dati in questo modo impiega almeno un algoritmo di machine learning.
Anche se è impossibile elencare ogni singolo caso d’uso del machine learning, un’occhiata alle più recenti storie di successo identifica alcuni esempi particolarmente evidenti.
- Identificazione dei messaggi di spam nella posta elettronica.
- Segmentazione del comportamento dei clienti per predisporre messaggi pubblicitari mirati.
- Previsioni meteorologiche e su cambiamenti climatici a lungo termine.
- Riduzione delle transazioni fraudolente tramite carta di credito.
- Stime fattuali dei danni economici a seguito di trombe d’aria e altri disastri naturali.
- Predizione dei risultati delle elezioni.
- Sviluppo di algoritmi per il pilotaggio automatico di droni e automobili.
- Ottimizzazione dell’uso dell’energia nelle abitazioni e negli uffici.
- Proiezione delle aree in cui è più probabile si verifichino attività criminali.
- Scoperta di sequenze genetiche correlate a determinate malattie.
I limiti del machine learning
Sebbene il machine learning sia ampiamente utilizzato e offra incredibili potenzialità, è importante comprenderne i limiti. Il machine learning, attualmente, emula un sottoinsieme relativamente limitato delle capacità del cervello umano. Offre una scarsa flessibilità in termini di estrapolazione al di fuori di rigidi parametri e non conosce il buonsenso. Detto questo, occorre applicare un’estrema cautela nel considerare esattamente che cosa ha imparato un algoritmo, prima di lasciarlo libero di operare nel mondo reale.
Senza una vita di esperienze passate su cui contare, i computer sono limitati anche nella loro capacità di creare semplici inferenze sui successivi passi logici da intraprendere. Prendete, per esempio, i banner pubblicitari presenti in molti siti web. Questi vengono proposti all’utente in base a schemi appresi mediante tecniche di data mining sulla cronologia di navigazione di milioni di utenti. Sulla base di questi dati, qualcuno che navighi in siti web dove si vendono scarpe è interessato ad acquistare scarpe e pertanto dovrà vedere pubblicità di scarpe. Il problema è che questo diviene un ciclo senza fine, in cui, anche dopo l’acquisto delle scarpe, verranno presentate nuove pubblicità di scarpe, invece di pubblicità di lacci e lucidi.
Google, Apple e Microsoft sono piuttosto sicure della loro capacità di offrire servizi ad attivazione vocale di assistenza, come Google Assistant, Siri e Cortana. Tuttavia, questi servizi piuttosto spesso faticano a rispondere a domande relativamente semplici. Inoltre, i servizi di traduzione online talvolta interpretano erroneamente frasi che anche un bambino piccolo comprenderebbe immediatamente, e la funzionalità di predizione del testo presente in molti dispositivi ha portato allo sviluppo di numerosi siti umoristici di errori di autocorrezione che illustrano la capacità dei computer di comprendere semplici parole ma sbagliando clamorosamente il contesto.
Alcuni di questi errori certamente sono prevedibili. La lingua umana è complicata, dotata com’è di più livelli di testo e sottintesi, e perfino gli esseri umani talvolta sbagliano il contesto. Nonostante il fatto che il machine learning sta migliorando rapidamente nell’elaborazione del linguaggio umano, le sue continue carenze illustrano un fatto importante: la qualità del machine learning dipende dalla qualità dei dati da cui apprende. Se il contesto non è esplicito nei dati di input, allora proprio come un essere umano, il computer farà del suo meglio per tentare di indovinare il significato della frase in base ai limiti delle sue esperienze passate.
L’etica del machine learning
Fondamentalmente, il machine learning è uno strumento che ci assiste nel cercare di trarre un significato dalla complessità dei dati del mondo. Come qualsiasi altro strumento, può essere impiegato in modo buono o cattivo. I casi in cui il machine learning sbaglia di più è quando è applicato in modo così vago, o così insensato, da trattare gli esseri umani come cavie da laboratorio, automi o consumatori decerebrati. Un processo apparentemente innocuo può condurre a conseguenze imprevedibili, quando vengono automatizzate da un computer privo di emozioni. Per questo motivo, coloro che impiegano il machine learning o il data mining sarebbero negligenti se non considerassero le implicazioni etiche del loro lavoro.
Un racconto, probabilmente apocrifo, riguarda un grosso rivenditore degli Stati Uniti, che ha impiegato il machine learning per identificare le future madri per l’invio di appositi coupon. Il rivenditore sperava che se queste future madri avessero ricevuto sconti interessanti, sarebbero poi diventate clienti fedeli, che poi avrebbero acquistato grandi quantità di pannolini, accessori per bambini e giocattoli.
Armato dei suoi metodi di machine learning, il rivenditore ha identificato gli articoli presenti nella cronologia degli acquisti che fossero in grado di far prevedere, con un elevato grado di sicurezza, non solo che una donna era in attesa, ma anche la data approssimativa della futura nascita.
Dopo che il rivenditore ha impiegato questi dati per una mailing list promozionale, un tizio, arrabbiato, ha risposto chiedendo spiegazioni: come mai sua figlia aveva ricevuto dei coupon per articoli di maternità? Era furioso, perché il rivenditore sembrava incoraggiare gravidanze da teenager! La storia prosegue, con la catena di negozi che offre le proprie scuse, seguite poi dalle scuse del padre, che, dopo aver parlato con sua figlia ha scoperto che, in effetti, era in dolce attesa!
La macchina apprende anche i nostri errori di valutazione
Man mano che gli algoritmi di machine learning vengono applicati sempre più, scopriamo che i computer possono apprendere alcuni comportamenti sconsiderati delle società umane. Purtroppo, tutto ciò comprende il fatto di perpetuare le discriminazioni di razza o genere e il rafforzamento degli stereotipi negativi. Per esempio, i ricercatori hanno scoperto che il servizio di pubblicità online di Google presenta con maggiore probabilità offerte di lavoro ad alto reddito agli uomini che alle donne ed è più propenso a mostrare messaggi sulla valutazione del background criminale alle persone di colore.
Per dimostrare che questi tipi di passi falsi non si limitano alla Silicon Valley, un servizio chatbot per Twitter sviluppato da Microsoft è stato prontamente messo offline dopo che aveva iniziato a diffondere propaganda filonazista e antifemminista. Spesso, degli algoritmi che a prima vista sembrano content neutral iniziano ben presto a riflettere le opinioni della maggioranza o le ideologie dominanti. Un algoritmo creato da Beauty.AI per riflettere un canone oggettivo di bellezza umana ha dato origine a controversie, in quanto favoriva quasi esclusivamente le opinioni dei bianchi. Immaginiamo le conseguenze se un concetto di questo tipo fosse stato applicato a un software di riconoscimento facciale per la prevenzione di attività criminali!
Quando il machine learning non sa trattare la privacy
A parte le conseguenze legali, un utilizzo inappropriato dei dati può essere dannoso a prescindere da tutto. I clienti possono non sentirsi a loro agio o addirittura spaventarsi vedendo resi pubblici certi aspetti della loro vita che considerano privati. Negli ultimi anni, un certo numero di applicazioni web di alto profilo ha sperimentato un esodo di massa di utenti che si sono sentiti sfruttati, quando i termini di servizio dell’applicazione sono stati cambiati o i loro dati sono stati utilizzati per finalità che andavano oltre quello che gli utenti avevano concordato originariamente. Il fatto che le aspettative sulla privacy differiscano per contesto, età e cultura complica ulteriormente la decisione su quale possa essere un uso appropriato dei dati personali. Sarebbe saggio considerare le implicazioni culturali del proprio lavoro prima di intraprendere un nuovo progetto, oltre a considerare le sempre più restrittive leggi promulgate dall’Unione Europea: il General Data Protection Regulation (GDPR) e le inevitabili politiche che ne discendono.
Il machine learning in mano agli hacker
Infine, è importante notare che mentre gli algoritmi di machine learning divengono sempre più importanti nella nostra vita quotidiana, crescono anche gli incentivi a un loro utilizzo e sfruttamento da parte di soggetti pericolosi. Talvolta, gli hacker “sportivi” vogliono semplicemente mettere a soqquadro gli algoritmi per farsi quattro risate e per avere un attimo di notorietà, come nel caso del “Google bombing” il metodo crowd–source per ingannare gli algoritmi di Google e spingerli a valutare in modo particolarmente elevato la pagina desiderata.
Le conseguenze degli attacchi fraudolenti agli algoritmi di machine learning possono addirittura essere fatali. I ricercatori hanno dimostrato che creando un adversarial attack che distorce in modo subdolo un segnale stradale con graffiti attentamente configurati, un hacker può indurre un veicolo a guida autonoma a interpretare erroneamente un segnale di stop, causando potenzialmente un incidente. Ma anche in assenza di intenti malvagi, i bug e gli errori umani hanno già condotto a incidenti fatali, che hanno coinvolto veicoli a guida autonoma Uber e Tesla. Dati questi esempi, è di primaria importanza ed è un obiettivo etico fondamentale che gli addetti al machine learning si preoccupino del fatto che i loro algoritmi siano ben utilizzati e non abusati nel mondo reale.
Immagine di apertura di ray rui su Unsplash.
Questo articolo richiama contenuti dal capitolo 1 di Machine Learning con R.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Machine Learning & Big Data per tutti

Data governance: diritti, licenze e privacy

Comunicazione digitale Food & Wine - Iniziare Bene
Libri che potrebbero interessarti

Machine Learning con Python - nuova edizione
Costruire algoritmi per generare conoscenza
Machine Learning con R
Conoscere le tecniche per costruire modelli predittivi