

Trasformare noiosa manualità in prezioso automatismo
Mi è accaduto diverse volte di dover recuperare da Internet informazioni per formare dataset che altrimenti non avrei avuto a disposizione, come una serie di titoli di film e la relativa trama in italiano; il modo più semplice e ovvio sarebbe stato copiare manualmente ciascuna sinossi e salvarla in un foglio di calcolo, ma è un compito che di certo non può essere svolto se i film da analizzare sono migliaia, perché richiederebbe giorni di lavoro noioso.
Esistono tantissime librerie in Python che permettono questo tipo di attività: per esempio, per estrarre dal sito www.filmtv.it i film usciti nel 2019, con titolo, genere, durata e votazione, utilizzeremo Beautiful Soup. Questo pacchetto contiene centinaia di funzioni utili per l’analisi di documenti in formato HTML e XML, come appunto le pagine Web, sfruttando la struttura ad albero dei documenti per dedurre informazioni. Cominciamo!
Analisi di una pagina web per fare scraping
Analizziamo velocemente, usando l’ispezione di Chrome, la pagina Web per individuare le informazioni che ci interessano: digitiamo allora nel campo di ricerca del browser https://www.filmtv.it/film/migliori/anno-2019/ e premiamo il tasto F12: dovremmo vedere una cosa simile a quella di seguito.
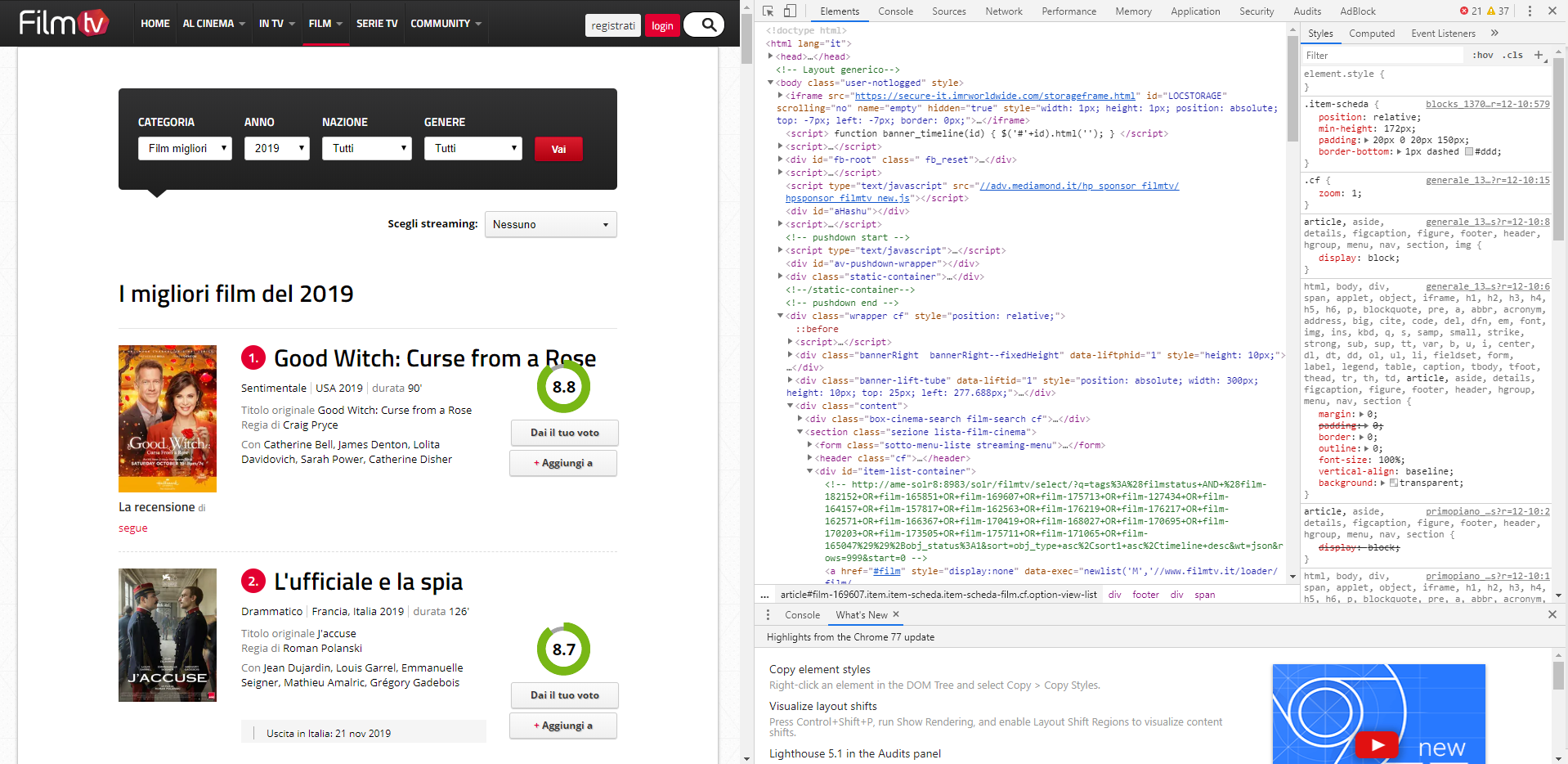
Analisi delle informazioni dentro una pagina web.
Il prossimo passo è cliccare sull’icona del mouse in alto nel riquadro appena aperto e usarlo per muoverci all’interno dei contenuti della pagina; vogliamo individuare in che punto del documento HTML si trovano il titolo del film e le altre informazioni che ci interessano.
Lo studio della struttura mostra come essa, a un certo punto, diventi ripetitiva: un tag article delimita la sezione del film in questione e al suo interno compare una serie di div che contengono i dati che vogliamo, perlopiù all’interno di una tabella o delle intestazioni. Il modello che dobbiamo sfruttare è il seguente:
<article class="item item-scheda item-scheda-film cf option-view-list" id="film-182152" data-position="1"> <div class="item-scheda-wrap"> <header> <h2 class="title-item-scheda"><span class="num">1.</span> <a href="//www.filmtv.it/film/182152/good-witch-curse-from-a-rose/" title="Good Witch: Curse from a Rose">Good Witch: Curse from a Rose</a></h2> </header> <div class="info-wrap"> <ul class="info cf"> <li>Sentimentale</li> <li>USA <time>2019</time> </li> <li><span>durata</span> 90'</li> </ul> <p class="titolo-originale"><span>Titolo originale</span> Good Witch: Curse from a Rose</p> <p class="regia"><span>Regia di</span> Craig Pryce</p> <p class="cast"><span>Con</span> Catherine Bell, James Denton, Lolita Davidovich, Sarah Power, Catherine Disher</p> </div> […] <footer> <div class="ring ring65p voto9" data-updcls="voto-ftv-film-182152"> <span data-updcnt="voto-ftv-film-182152">8.8</span> […] </article>
Per poter lavorare con queste informazioni, dobbiamo pensare di analizzare i tag, a partire da article, come un albero: man mano che ci addentriamo nei suoi rami, individuiamo e salviamo le informazioni che ci interessano.
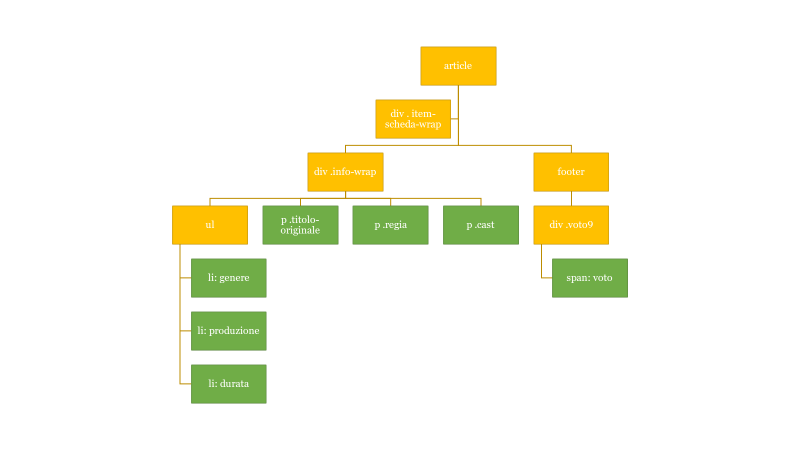
La struttura di informazioni nel web come un albero di cui esplorare i rami.
I riquadri in verde sono quelli che ci interessano di più e li definiamo foglie dell’albero. Per poterci arrivare facilmente, sfruttiamo le classi che gli sono state assegnate (quelle con il nome che inizia con un punto), così da poterle selezionare per recuperarne il valore.
Mettiamo mano al codice!
Vediamo quindi come recuperare queste informazioni da un singolo tag article, dopo di che, siccome fare la stessa cosa per tutti gli altri tag analoghi presenti nella pagina è un’attività ripetitiva, utilizzaremo un’istruzione ciclica che compia gli stessi passi per ogni tag article.
Creiamo un oggetto di tipo BeautifulSoup che ci permetterà di navigare all’interno del documento HTML:
# creazione di un oggetto "soup" soup = BeautifulSoup(data) print(soup)
Per recuperare il titolo, possiamo utilizzare la funzione find() che accetta come input diversi parametri, tra cui il nome del tag di interesse ed eventuali attributi dello stesso, come classe, ID e così via. In questo caso dobbiamo sfruttare la classe titolo-originale, per poter prendere il contenuto del tag; all’interno del paragrafo c’è però un tag span che non ci interessa. Con il metodo decompose() lo eliminiamo e con l’attributo text recuperiamo invece il testo del paragrafo, ovvero il titolo del film:
paragrafo = soup.find('p', attrs = {'class': 'titolo-originale'})
print(paragrafo)
paragrafo.find('span').decompose()
titolo = paragrafo.text
print(titolo)
Il procedimento per la regia e il cast è analogo:
# REGIA
paragrafo = soup.find('p', attrs = {'class': 'regia'})
print(paragrafo)
paragrafo.find('span').decompose()
regia = paragrafo.text
print(regia)
# CAST
paragrafo = soup.find('p', attrs = {'class': 'cast'})
print(paragrafo)
paragrafo.find('span').decompose()
cast = paragrafo.text
print(cast)
Per quanto riguarda il genere, la produzione e la durata, questi sono contenuti all’interno di un ul, ovvero una lista non ordinata di elementi. Dal momento che l’ordine di comparizione dei tre è sempre lo stesso, possiamo pensare semplicemente di iterare all’interno della lista di elementi li e di salvarne il contenuto in un array, che poi scompatteremo nelle diverse variabili:
# GENERE, PRODUZIONE, DURATA
elements = soup.find('ul')
print(elements)
arr = []
genere = ''
prod = ''
durata = ''
for li in elements.findAll('li'):
arr.append(li.text)
print(arr)
genere = arr[0]
prod = arr[1].rstrip()
durata = arr[2]
print(genere)
print(prod)
print(durata)
Non è il metodo migliore, ma è comunque quello più veloce! 😊
Recuperiamo infine il voto della recensione: il meccanismo è sempre lo stesso. Individuiamo il div tramite la classe voto9 e preleviamo il contenuto del tag span, da cui riceveremo il voto del film:
# VOTO
div = soup.find('div', attrs={'class': 'voto9'})
voto = div.find('span').text
print(voto)
Et voilà! Les jeux sont faits.
Se volessimo salvare il tutto in una tabella, o in un foglio di calcolo, potremmo sfruttare il pacchetto pandas: creando un dataframe, ovvero una tabella, con le colonne definite come di seguito, possiamo inserire i nostri dati e poi salvarli in un documento xlsx, così:
# preparo i dati
data = [[titolo, genere, prod, durata, regia, cast, voto]]
# creazione di un dataframe, che utilizzeremo per salvare i nostri dati
df = pd.DataFrame(data, columns=['titolo', 'genere', 'produzione', 'durata', 'regia', 'cast', 'voto'])
print(df)
df.to_excel("output.xlsx")
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Libri che potrebbero interessarti

Analisi del linguaggio con Python
Imparare a processare testo e audio con le librerie open source
Imparare a programmare con Python
Il manuale per programmatori dai 13 anni in su