

Ti sei mai chiesto come chatbot come Siri, Alexa e Cortana siano in grado di rispondere alle domande poste dagli utenti? Tutti questi prodotti hanno una cosa in comune: lavorano tramite meccanismi di intelligenza artificiale (spesso abbreviata in AI).
In questo articolo analizzeremo una semplice rete neurale software, che è uno dei principali mattoni dell’intelligenza artificiale. Esistono diverse varianti di una rete neurale, dedicate alla risoluzione di problemi particolari.
Le reti neurali non sono tutte uguali
Ad esempio, le reti neurali convoluzionali vengono comunemente utilizzate per problemi di riconoscimento delle immagini, mentre le reti neurali ricorrenti vengono utilizzate per risolvere i problemi di sequenza.
In questo primo esempio lasceremo però da parte questi concetti e altri, come il deep learning, che vengono spesso associati al tema e confusi con esso: faremo chiarezza più avanti.
Che cos’è una rete neurale nella pratica
Una rete neurale può essere vista come una funzione matematica che produce un output desiderato a partire da un dato input. I componenti principali possono essere riassunti in:
- un layer di input;
- un numero x di layer nascosti;
- un layer di uscita.
A questi tre vanno certamente aggiunti determinati pesi per ogni collegamento tra un layer e l’altro, nonché una funzione di attivazione per ciascun layer.
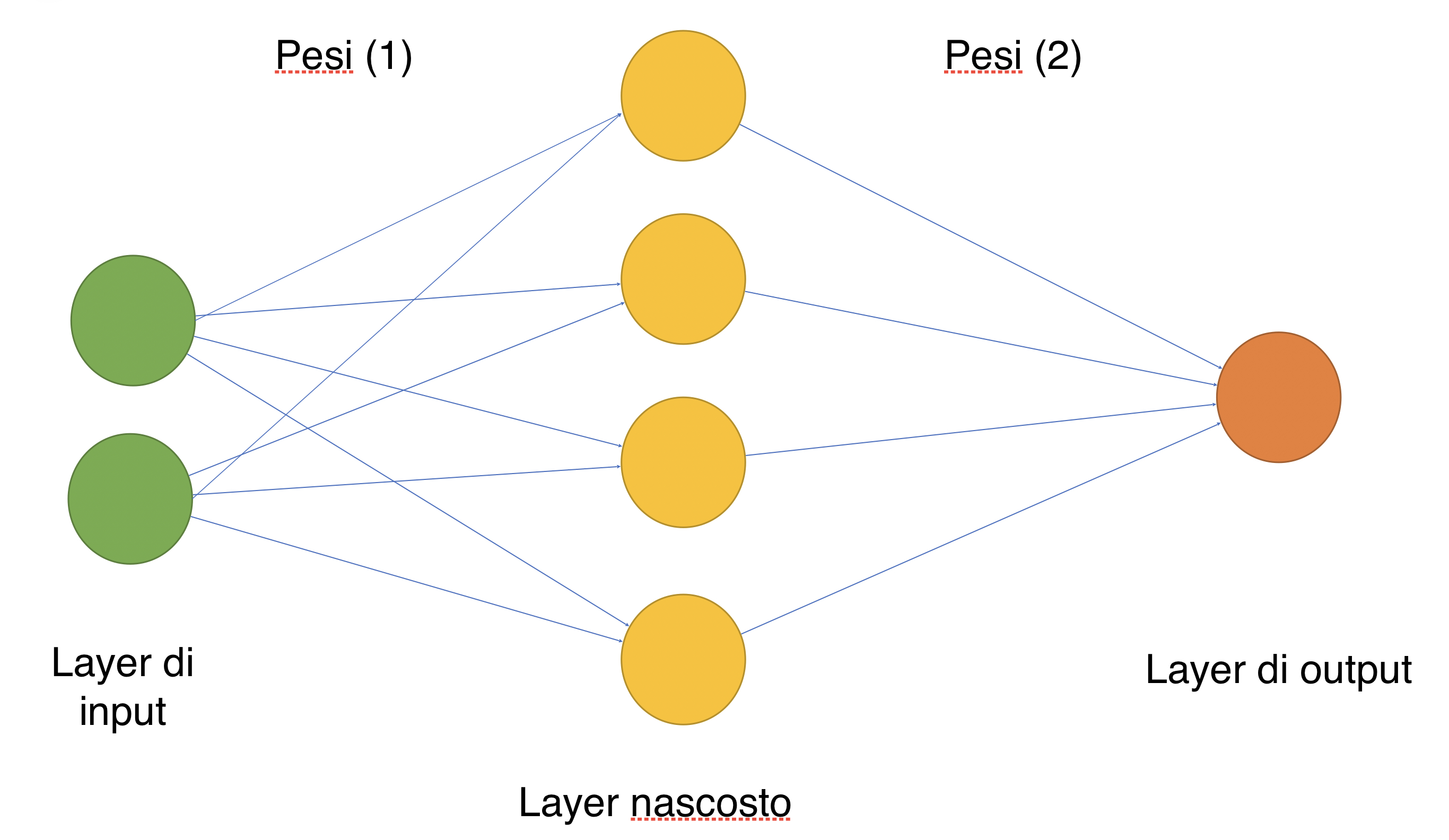
Un esempio molto semplice di rete neurale a due strati.
Qui sopra appare un esempio di rete neurale a due strati (lo strato di input non viene considerato nel conteggio); a partire da uno strato di input, tramite diversi collegamenti con lo strato nascosto che hanno un set di pesi, viene prodotto un risultato che verrà restituito dal layer di output.
Addestriamo una rete neurale
Le reti neurali, come accennato inizialmente, vengono utilizzate per risolvere problemi relativamente complessi, come il riconoscimento di immagini o di testo a partire da un’immagine; in questo caso, addestreremo una rete neurale a calcolare il risultato corretto a partire dai seguenti input:
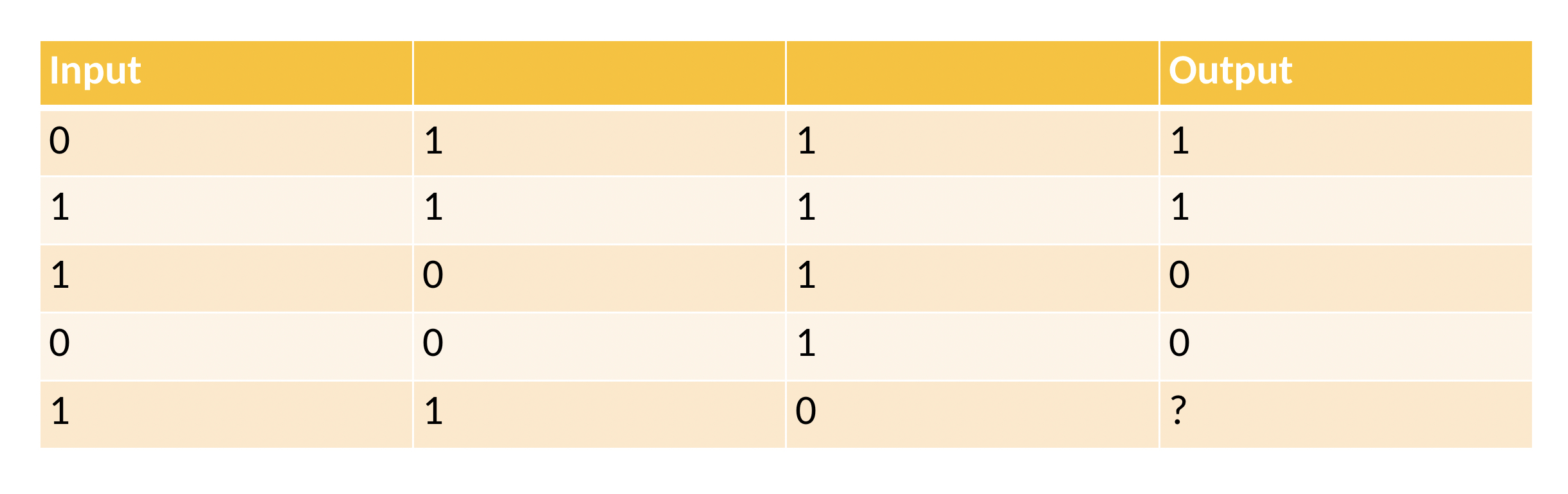
Input sottoposto a una semplice rete neurale.
In questo caso, il valore in output è sempre uguale al secondo valore inserito in input; il risultato della nuova situazione dovrebbe dunque essere 1.
Creiamo una classe per addestrare la rete
Il primo step è creare una classe che permetta di addestrare la rete. La funzione di attivazione che verrà utilizzata dai layer è la funzione sigmoide: questa funzione prende il nome dalla curva a forma di S che produce tramite i suoi input. La sigmoide può mappare qualsiasi valore compreso tra 0 e 1; avendo un dataset binario, è la funzione perfetta per la rete neurale di questo caso di studio.
Ogni input avrà un peso, positivo o negativo; ciò implica che un input con un numero elevato di peso positivo o un numero elevato di peso negativo influenzerà maggiormente l’output risultante. In questo caso, abbiamo iniziato assegnando ad ogni peso un numero casuale. Gli step successivi sono i seguenti:
- i dati di input vengono normalizzati;
- viene calcolato il tasso di errore, che permette di correggere e migliorare il risultato in output. In questo caso, sarà la differenza tra l’output previsto dal neurone e l’output previsto dal set di dati di training;
- sulla base dell’entità dell’errore ottenuto, vengono eseguite alcune piccole rettifiche di peso utilizzando la sigmoide derivativa.
Questo processo viene arbitrariamente ripetuto 20 mila volte. In ogni iterazione, l’intero set di training viene elaborato contemporaneamente.
Ma ora, mani nel codice! L’obiettivo è definire la classe ReteNeurale, i pesi assegnati secondo numeri casuali, le funzioni sigmoide e sigmoide_der:
import numpy as np class ReteNeurale():
def __init__(self):
np.random.seed(1)
self.pesi = 2 * np.random.random((3, 1)) - 1
def sigmoide(self, x): return 1 / (1 + np.exp(-x))
def sigmoide_der(self, x): return x * (1 - x)
Ѐ necessario definire due funzioni che permettano in primis l’addestramento della rete, e poi la produzione di un risultato a fronte di un nuovo input, utilizzando il modello addestrato:
def train(self, training_inputs, training_outputs, iterazioni): for iteration in range(iterazioni): # calcolo dell'output a partire dall'input output = self.calcola(training_inputs) # calcolo del tasso di errore error = training_outputs - output # calcolo delle correzioni secondo il tasso di errore adj = np.dot(training_inputs.T, error * self.sigmoide_der(output))
self.pesi += adj
def calcola(self, inputs): inputs = inputs.astype(float) # applicazione della funzione sigmoide agli input output = self.sigmoide(np.dot(inputs, self.pesi)) return output
A questo punto, è possibile testare la rete neurale con i valori presenti nel dataset di esempio visto in precedenza: tramite la libreria numpy, è possibile inserire i dati di input all’interno di una matrice che verrà utilizzata come input, mentre i valori di output saranno inseriti in un array, che verrà poi trasposto in questo modo:
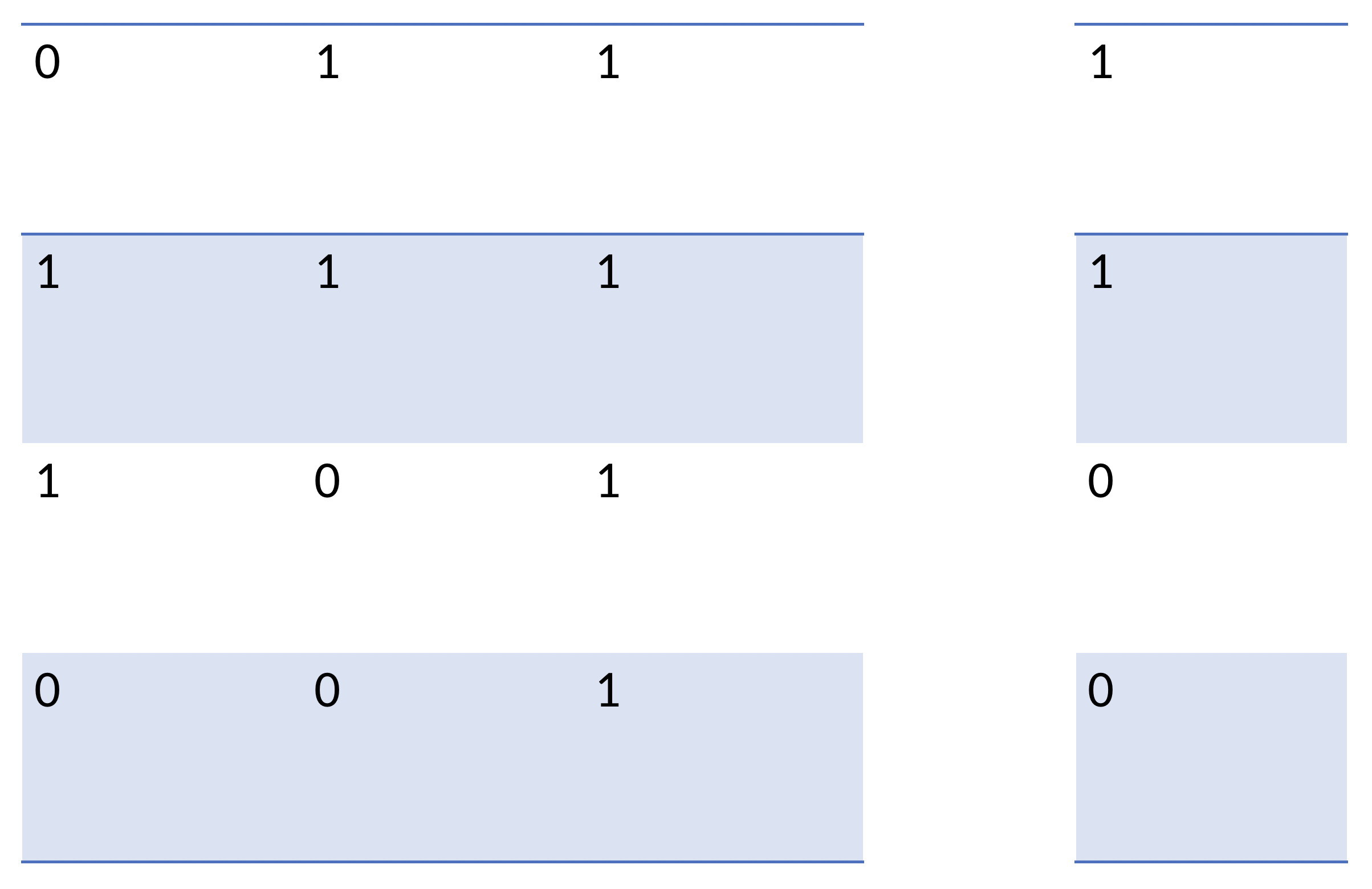
Trasposizione dell’array contenente i valori di output
if __name__ == "__main__": # inizializzazione della rete neurale rete_neurale = ReteNeurale()
training_inputs = np.array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_outputs = np.array([[0, 1, 1, 0]]).T
# addestramento della rete rete_neurale.train(training_inputs, training_outputs, 20000)
Addestramento completato, sotto con i dati
Dopo aver addestrato la rete, l’ultimo passo da compiere è inserire nuovi valori, di cui la rete non conoscerà l’output:
#inserimento di nuovi dati, senza l'output
print("Nuovo input: ", 1, 1, 0)
print(rete_neurale.calcola(np.array([1, 1, 0])))
Il risultato prodotto sarà il seguente:
Nuovo input: 1 1 0
[0.99996185]
Il numero 0.9999… è molto vicino a 1, ovvero al risultato sperato. In questo caso, la rete neurale è estremamente semplice e i dati di input poco significativi, ma le potenzialità che è possibile intravedere sono grandi.
A un prossimo articolo!
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Data governance: diritti, licenze e privacy

Big Data Analytics - Iniziare Bene

Agile, sviluppo e management: iniziare bene
Libri che potrebbero interessarti

Analisi del linguaggio con Python
Imparare a processare testo e audio con le librerie open source
Data Science
Guida ai principi e alle tecniche base della scienza dei dati